TurboFan RUL Prediction
Remaining useful life prediction for turbofan engines using sliding-window features, GRU sequence modeling, random forests, and regularized linear baselines on NASA N-CMAPSS data.
TurboFan RUL Prediction
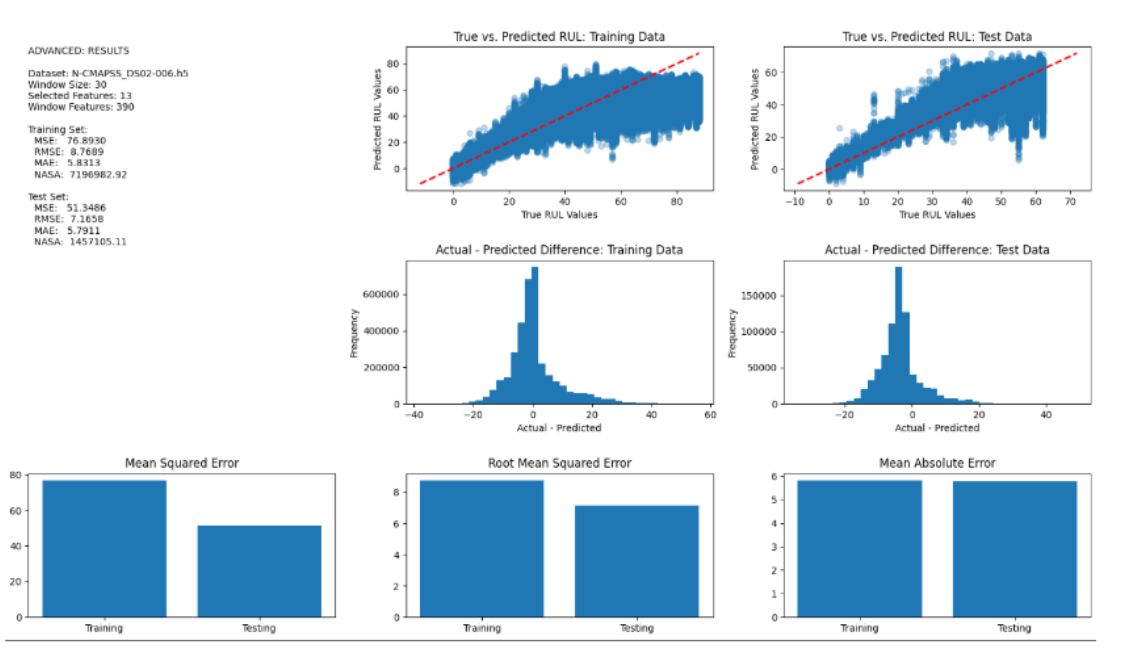
TurboFan RUL Prediction is a machine learning project focused on predictive maintenance for aircraft engines using NASA N-CMAPSS multivariate time-series data. The project studies how sensor trajectories, operating conditions, and recent degradation history can be used to estimate remaining useful life (RUL) before failure. Rather than relying on a single model family, the system compares three approaches: a regularized linear baseline, a random forest regressor, and a GRU-based sequence model tuned with Optuna. The pipeline includes HDF5 data loading, exploratory analysis, engine-level train/validation/test splitting, feature selection, sliding-window sequence construction, and evaluation with RMSE, MAE, and NASA’s asymmetric scoring metric. The final results showed the GRU as the strongest model, highlighting the value of temporal modeling for degradation prediction.
Predicting remaining useful life from aircraft engine telemetry is challenging because the relationship between sensor measurements and failure is noisy, nonlinear, and history-dependent. This project explores how much model choice and temporal context matter when estimating engine degradation from real multivariate sequence data.